This article provides basic information on determining the serial number of hard drives and potential defects.
How to determine the serial number of a drive
In Windows
There is a tool in Windows which enables you to read the serial numbers of one or several drives. The program is called DiskID32 and is Open Source.
You can download the tool here.
First, open the program directory with the console and enter the following command:
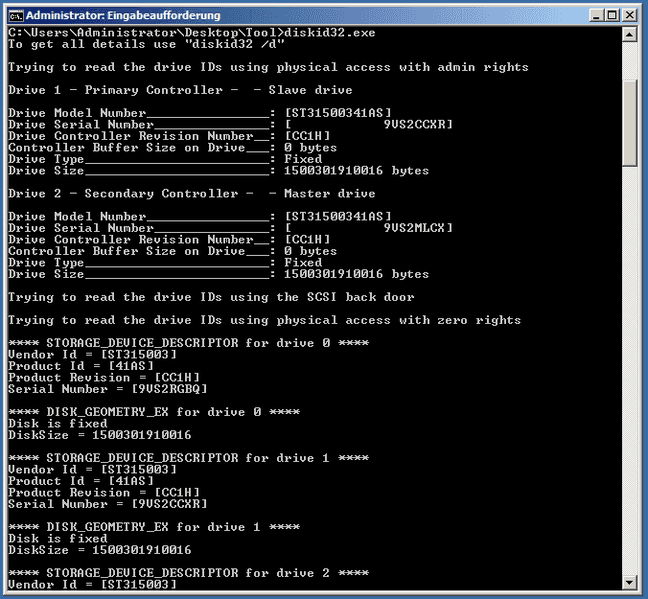
diskid32.exeYou will receive more information about your drive(s).
Look at the information under each drive. You can see the serial number for each drive next to Drive Serial Number.
Example:
In Linux
There are two solutions for determining the serial number, the first one with udevadm:
/sbin/udevadm info --query=property --name=sda | grep ID_SERIALand the second solution with hdparm:
Open your terminal and enter the following command:
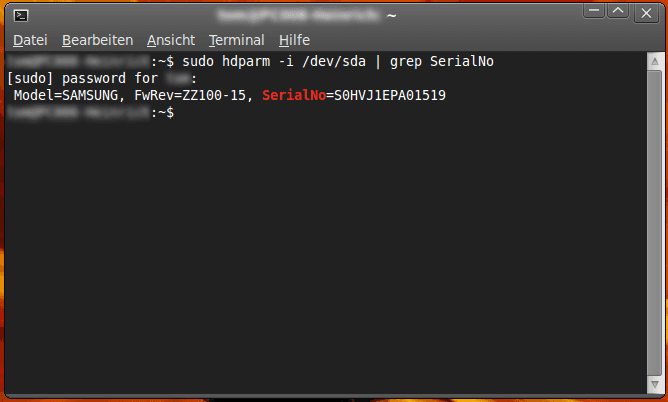
sudo hdparm -i /dev/sda | grep SerialNoWith sudo, you will receive the administrator rights which you need for reading information from the drive. You can call up a function using hdparm, which provides you with information about the drive.
With -i /dev/sda, you can assign hdparm a parameter which will provide you with concrete information about the drive.
However, the hardware that you want to check can vary from the interface:
- IDE / ATA device:
-i /dev/hd[a-t] - SCSI / SATA device:
-i /dev/sd[a-z]
Next, filter the serial number of the drive from the output using | grep SerialNo.
If this command returns an error, you probably will need to install the program itself:
sudo apt-get install hdparmExample:
In FreeBSD
You can use the following command in FreeBSD:
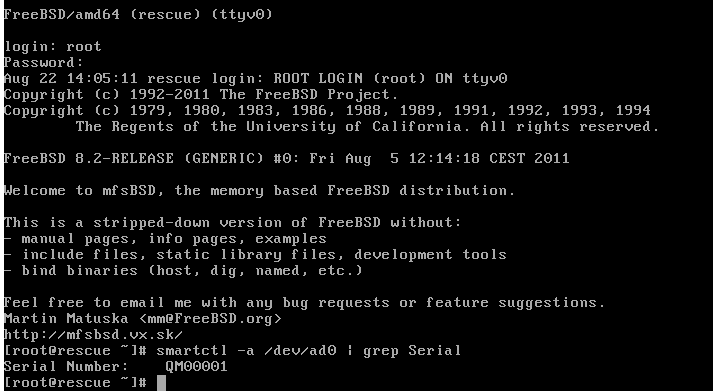
smartctl -a /dev/ad0 | grep Serialsmartctl is a function which enables you to read drive information.
With the -a parameter, you can see all available information for the first assigned drive.
The various interfaces for devices also apply here:
- IDE / ATA device:
-a /dev/ad[0-9]+ - SCSI device:
-a /dev/da[0-9]+OR-a /dev/pass[0-9]+ - SATA device:
-a /dev/ada[0-9]+
With | grep Serial, you are able to filter the serial number of the drive from the information.
Example:
Information on defective drives
To detect damaged drives, it is advisable to use a tool for recognizing such errors.
We use Smartmontools on Windows, Linux and FreeBSD.
In Windows
If you have not yet installed Smartmontools on your Windows Server 2008, you can download the latest version here.
ATTENTION: During the setup you must put a check next to PATH variable. Or, you can set the path for this program in the environment variables.
Once you have successfully installed the tool, you can open the command prompt.
Enter the following command to check whether the program is usable:
smartctl -hAt the command prompt, you should now see a list of commands that you can use for smartctl.
As smartctl behaves in exactly the same way as it does in Linux, you can use the same commands in Windows. The path name for the types of partition also remains the same.
Therefore, you will need to use the same parameters in Windows as those for Linux.
Be aware of the different interfaces for devices:
- IDE / ATA devices:
-H /dev/hd[a-t] - SCSI / SATA devices:
-H /dev/sd[a-z]
WARNING: Normal drive names such as c:, do not work!
In Linux
With Linux systems, messages from the kernel as well as Smartmontools provide information about a defective drive.
You can display kernel messages using dmesg. Here it is particularly important to pay attention to messages beginning with ata. You could use the dmesg | grep ata command here, for example.
First, you need to install the Smartmontools on Linux Systems. The packet ID will differ in the systems:
- Debian:
smartmontools - Fedora:
kernel-utils
You need to have administrator rights for the installation.
Next, you can continue work in the console.
(Important note: You need administrator rights for the entire process.)
Enter the following command in the console:
smartctl -H /dev/sdaBe aware of the different interfaces for devices:
- IDE / ATA devices:
-H /dev/hd[a-t] - SCSI / SATA devices:
-H /dev/sd[a-z]
This instruction queries the condition of your drive. You will receive a message informing you if the drive can continue to be used.
If FAILED! is shown, then something is wrong with your drive.
If PASSED appears, then your drive is OK.
If you would like a more exact result for your drive, you can use the provided chart. You can find this by using the same command under Failed Attributes:.
You can find an explanation of the attributes in the section Measured Values for Attributes.
If you now evaluate your chart using the measured values, you will receive an overview of the errors on your drive.
If you would like to detect all possible errors on your drive, you can use the command smartctl -A /dev/sda.
(BE AWARE of your device types here.)
This time, you will see all available errors. You can now evaluate the chart.
You can find an explanation of the attributes in the section List of Attributes.
In FreeBSD
It is worth taking a look at the kernel messages (dmesg) in FreeBSD to find out more about any drive defects.
As with Windows and Linux, you need to install Smartmontools in the package management.
You can use the following command for this:
pkg_add -r -v smartmontools(Important note: You need to have administrator rights for the entire process.)
As with Linux, you can use the same smartctl commands in FreeBSD.
However, there is one small difference for the path name of the drive.
Instead of the usual path details, for example, /dev/hd[a-t] and /dev/sd[a-z],
use the new path: /dev/ad[0-9]+.
List of Attributes
| Parameter Name | Description |
|---|---|
| Raw Read Error Rate | Critical. A lower value indicates uncorrectable read errors related to the drive surface or the magentic heads. |
| Througput Performance | Critical. A general indicator of throughput performance. Lower values show that the disk is no longer able to work at full speed. |
| Spin Up Time | Average period of time taken by the drive to accelerate its disks. Poor values may indicate problems with storage, which often come from being stored at too high a temperature. |
| Start/Stop Count | Non-critical. Counts the number of start/stop cycles for the drive. |
| Reallocated Sector Count | Very critical. Counts how many reserve sectors have been allocated by the hard drive. Indicates media problems. |
| Read Channel Margin | Indicates how much bandwidth is used on average for read operations. The exact description is not documented. |
| Seek Error Rate | Critical. Counts the frequency of errors during read operations, which depends on the condition of the positioning system or the surface. |
| Seek Time Performance | General value that describes the performance of the seek operation of the magnetic heads. Lower values indicate mechanical problems. |
| Power On Hours Count | Counts the number of hours in power-on state. The format mostly depends on the manufacturer. |
| Spin Retry Count | Critical. Indicates the number of attempts needed to start so that the disk can reach its fully operational speed. |
| Recalibration Retries | Critical. Counts how often the disk needs to recalibrate the read/write heads. Indicates mechanical malfunction. |
| Device Power Cycle Count | Shows statistics for how often the hard drive is switched on and off. |
| Soft Read Error Rate | Indicates how often the operating system has reported an error when reading data from a disk. |
| G-Sense Error Rate | G-Sense stands for a shock sensor, which measures strong vibrations during operation. |
| Power-Off Retract Cycle | Ultimately, shows a count of how often the hard disk was powered down. |
| Load/Unload Cycle Count | Indicates how often the disk has put its read/write heads into the park position (landing zone position). |
| Temperature | Specifies the temperature for the drive. It's not important, as the values are usually very inaccurate for most devices. |
| Reallocation Events Count | Very critical. Counts every attempt by the disk to remap sectors even if this does not succeed. |
| Current Pending Sector Count | Very critical. Shows the number of unstable sectors which are waiting to be moved to a special reserved area. |
| Uncorrectable Sector Count | Very critical. The number of defective sectors which the internal logical drive cannot restore and move to the reserved area. |
| UltraDMA CRC Error Rate | Critical. The number of CRC errors during data transfer. May indicate defective cables, driver conflicts or to overclocking problems. |
| Write Error Rate | Critical. Counts the frequency of errors on writing sectors. |
| Disk Shift | Very critical. This value shows whether an imbalance has occurred due to problems with temperature or the effects of shock. |
| Loaded Hours | Indicates how long the disk has spent under data load. This is shown by the movement of the magnetic heads actuator. |
| Load/Unload Retry Count | Undocumented unit count for the number of loading retries when the read/write heads change position. |
| Load Friction | Shows a statistical value for the level of friction caused by loading on drive. |
| Load-in Time | Indicates how long the magnetic heads actuator was not in the landing zone position. |
| Torque Amplification Count | Counts the number of attempts by the internal logic of the drive to bring the rotation into line. |
| GMR Head Amplitude | A purely statistical value describing the distance of repetitive forward/reverse motion covered by the read/write heads. |
Measured Values for Attributes
| Attribute | Description |
|---|---|
| VALUE | Is a normalized measured value, which mostly counts backwards (the lower, the worse it is) |
| WORST | The worst value up to now. |
| THRESHOLD | The limit below which the value should not drop. |
| TYPE | Stands for the definition of the parameter: Pre-fail is a warning of failure soon, while Old age means that it is generally a matter of progressive aging. (The current temperature does not necessarily fall into one or the other categories.) |
| UPDATED | Shows whether the value is permanently (always) updated or if it is updated first through a self test of the Offline data collection type. |
| RAW_VALUE | Is the actual measured value, meaning the measured temperature or the error count. |
Creating a complete SMART log
To create a complete SMART log, use the command smartctl with the option -x. The specification of the drive is similar to the explanation under Information on defective drives.
Start a SMART Self Test
You can start the self test of the drive with smartctl and the option -t short or -t long. The specification of the drive is similar to the explanation under Information on defective drives.
This self test is a manufacturer-specific test, and it is performed from the drive firmware. You should not use the server during the test; using it could stop the test.
Drives with RAID controllers
In Windows
Adaptec has developed an administration tool for extracting drive information from a RAID system. This program is structured graphically and called Adaptec Storage Manager. You can download it here. For this, please use the user data contained in your confirmation email.
Install and start the program on your server. A graphical user interface will appear.
Next, click Direct Attached Storage in the box on the left. Look to the right in the drop-down menu. Double click on the installed operating system with the corresponding IP and system. A request for login data should follow. After you have logged in, a message will appear stating that a RAID controller has been found. Confirm with Register Later and then double click on the RAID controller.
A list of all the drives contained in the RAID controller will appear. Double click on your selected drive. A window will open where you can now retrieve the drive information.
In Linux
smartctl usually shows the serial number for the drive. However, there are special programs for various controllers:
3ware Controllers with tw_cli
tw_cli should be contained in the packet source of the distributions. Start tw_cli without specifying parameters:
tw_cliNow enter the command:
/cx/py show serialx stands for the controller number, with O y standing for the number of the drive.
Adaptec Controller with arcconf
In Linux you will need a tool called arcconf. You can download this program here.
Extract the file. Then move it:
mv arcconf-64 /usr/local/binNext, turn the arcconf into an executable file:
chmod +x /usr/local/bin/arcconfNow, execute the file:
/usr/local/bin/arcconfIt is possible that you will need to install libstdc++5 as well, as arcconfig requires this packet. Should this be the case, you can download the file here.
If a list of possible command parameters appears, the program is working correctly.
Now you can read the serial number of the drive using the command ./usr/local/bin/arcconf getconfig 1. The digit 1 , indicates which RAID controller is concerned.
However, please note that your drives in RAID will first be listed from Physical Device information. You can find the serial number for your drives in Serial number.
In addition to the serial numbers, this tool provides further useful information regarding your drives.
In FreeBSD
To obtain the drive serial number in FreeBSD, you need to enter the following command in the terminal:
portsnap fetch update
cd /usr/ports/sysutils/arcconf
make install clean && rehashThe command /usr/local/sbin/arcconf getconfig 1 enables you to access the drives. Please be aware here that the digit following getconfig indicates the RAID controller.
As with Linux, you can find various information about the drive and the Serial number in Physical Device information.