Dieser Artikel soll grundlegende Informationen zum Auslesen der Festplatteninformationen und Fehlersuche geben.
Ermitteln der Seriennummer einer Festplatte
Unter Windows
Unter Windows gibt es ein Tool, womit du die Seriennummern einer oder mehrerer Festplatten auslesen kannst. Das Programm nennt sich DiskID32 und ist OpenSource.
Du kannst das Tool hier herunterladen.
Öffne mit der Konsole das Programmverzeichnis und gib folgenden Befehl ein:
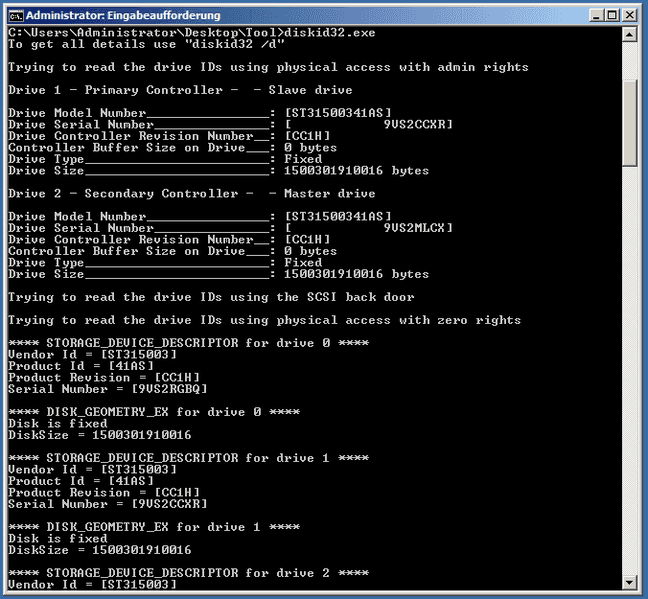
diskid32.exeDu erhältst mehrere Informationen über deine Festplatte(n).
Die Seriennummer(n) der ausgewählten Festplatte(n) findest du in Drive Serial Number.
Beispiel:
Unter Linux
- Möglichkeit 1 mit
udevadm:
/sbin/udevadm info --query=property --name=sda | grep ID_SERIAL- Möglichkeit 2 mit
hdparm:
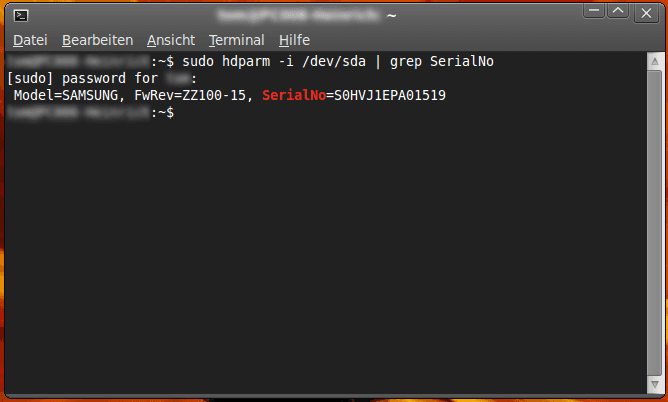
sudo hdparm -i /dev/sda | grep SerialNoMit sudo bekommst du Administratorenrechte, die du zum Lesen der Festplatteninformationen benötigst. Via hdparm rufst du eine Funktion auf, die dir Festplatteninformationen liefert.
Mit -i /dev/sda übergibst du hdparm einen Parameter, der dir konkrete Informationen zur Festplatte liefert.
Die zu überprüfende Festplatte kann jedoch von der Schnittstelle aus variieren:
- IDE / ATA Gerät :
-i /dev/hd[a-t] - SCSI / SATA Geräte :
-i /dev/sd[a-z]
Anschließend filterst du mit | grep SerialNo die Seriennummer der Festplatte aus der Ausgabe hinaus.
Wenn dieser Befehl einen Fehler zurückgibt, muss wahrscheinlich noch das Programm selbst installiert werden:
sudo apt-get install hdparmBeispiel:
Unter FreeBSD
Unter FreeBSD kannst du folgenden Befehl nutzen:
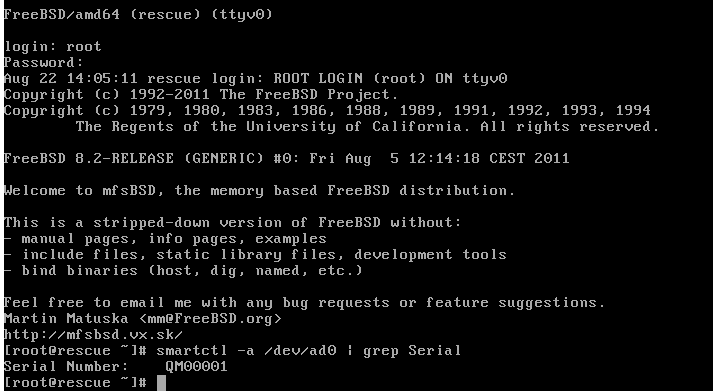
smartctl -a /dev/ad0 | grep Serialsmartctl ist eine Funktion, mit der du Festplatteninformationen lesen kannst.
Mit dem -a Parameter kannst du dir alle verfügbaren Informationen der zunächst übergebenen Festplatte anzeigen lassen.
Dabei gelten auch hier die verschiedenen Schnittstellen der Geräte:
- IDE / ATA Gerät :
-a /dev/ad[0-9]+ - SCSI Gerät :
-a /dev/da[0-9]+ODER-a /dev/pass[0-9]+ - SATA Gerät :
-a /dev/ada[0-9]+
Mit | grep Serial filterst du die Seriennummer der Festplatte aus den Informationen.
Beispiel:
Hinweise zu defekten Festplatten
Um beschädigte Festplatten zu erkennen, empfiehlt sich ein Tool zur Erkennung solcher Fehler.
Deshalb verwenden wir auf Windows, Linux und FreeBSD ein und dasselbe Tool: Smartmontools.
Unter Windows
Falls du Smartmontools noch nicht auf deinem Windows Server 2008 installiert haben solltest, lad dir die aktuelle Version hier herunter.
ACHTUNG: Setze während des Setup unbedingt den Haken bei PATH variable. Alternativ zu dieser Option kannst du in den Umgebungsvariablen den Pfad zu diesem Programm setzen.
Wenn das Tool erfolgreich installiert ist, kannst du die Eingabeaufforderung öffnen.
Gib folgenden Befehl ein, um zu prüfen, ob das Programm verwendbar ist:
smartctl -hEs sollte in der Eingabeaufforderung eine Liste mit Befehlen erscheinen, die du smartctl übergeben kannst.
Unter Windows verhält sich smartctl genau so, wie unter Linux. Deshalb kannst du die selben Befehle nutzen. Was ebenso gleich bleibt, ist die Pfadangabe zu den Partitionstypen.
Deshalb musst du unter Windows dieselben Parameter verwenden, wie unter Linux.
Achte deshalb auf die verschiedenen Schnittstellen der Geräte:
- IDE / ATA Geräte :
-H /dev/hd[a-t] - SCSI / SATA Geräte :
-H /dev/sd[a-z]
ACHTUNG: Normale Laufwerksnamen wie c:, funktionieren nicht!
Unter Linux
Unter Linux-Systemen bieten sowohl Meldungen des Kernels als auch die smartmontools Hinweise auf eine defekte Platte.
Kernelmeldungen können per dmesg angezeigt werden. Dort sollte besonders auf Meldungen geachtet werden, welche mit ata beginnen. Hier könntest du beispielsweise den Befehl dmesg | grep ata anwenden.
Die Smartmontools musst du auf Linux-Systemen erst installieren. Dabei variieren die Paketnamen unter den Systemen:
- Debian:
smartmontools - Fedora:
kernel-utils
Du benötigst für die Installation Administratorrechte.
Als Nächstes kannst du in der Konsole weiterarbeiten.
(Beachte, dass der gesamte Vorgang Administratorrechte benötigt)
Gib in der Konsole folgenden Befehl ein:
smartctl -H /dev/sdaAchte hier auf die verschiedenen Schnittstellen der Geräte:
- IDE / ATA Geräte :
-H /dev/hd[a-t] - SCSI / SATA Geräte :
-H /dev/sd[a-z]
Diese Anweisung befragt den Zustand deiner Festplatte. So erhältst du eine Meldung, die dir sagt, ob deine Festplatte weiterhin einsetzbar ist.
Wird als Ergebnis FAILED! angezeigt, dann ist mit deiner Festplatte etwas nicht in Ordnung.
Lautet das Ergebnis PASSED, dann ist mit deiner Festplatte alles in Ordnung.
Willst du von deiner Festplatte ein genaueres Ergebnis, dann kannst du die mit angelegte Tabelle nutzen. Diese findest du unter dem selben Befehl, ab Failed Attributes.
Eine Erklärung zu den Messwert-Attributen findest du im Abschnitt Messwert-Attribute.
Wenn du deine Tabelle mit den Messwerten nun auswertest, erhältst du eine Übersicht von Fehlern auf deiner Festplatte.
Wenn du alle möglichen Fehler von deiner Festplatte erkennen willst, kannst du
den Befehl smartctl -A /dev/sda verwenden.
(ACHTEN auch hier auf deinen Gerätetypen)
Dieses Mal werden alle verfügbaren Fehler angezeigt. Nun kannst du die Tabelle auswerten.
Eine Erklärung zu den Attributen findest du im Abschnitt Attribute-Liste.
Unter FreeBSD
Auch unter FreeBSD lohnt sich der Blick in die Meldungen des Kernels (dmesg), um weitere Hinweise auf den Defekt der Platte zu finden.
Gleich wie unter Windows und Linux, musst du die smartmontools in der Paketverwaltung installieren.
Dazu kannst du folgenden Befehl nutzen:
pkg_add -r -v smartmontools(Beachte, dass der gesamte Vorgang Administratorrechte benötigt)
Wie unter Linux kannst du auch in FreeBSD die selben smartctl-Befehle nutzen.
Allerdings gibt es zur Pfadangabe der Festplatte einen kleinen Unterschied.
Verwende statt den üblichen Pfadangaben wie z.B.: /dev/hd[a-t] und /dev/sd[a-z],
den neuen Pfad: /dev/ad[0-9]+.
Attribute-Liste
| Parametername | Bedeutung |
|---|---|
| Raw Read Error Rate | Kritisch. Ein niedriger Wert weist auf unkorrigierbare Lesefehler hin, die mit der Plattenoberfläche oder mit den Leseköpfen zusammen hängen. |
| Througput Performance | Kritisch. Allgemeiner Indikator für den Datendurchsatz. Niedrige Werte zeigen, dass die Platte nicht mehr in vollem Tempo arbeiten kann. |
| Spin Up Time | Mittlere Startzeit des Motors, der die Platten antreibt. Schlechte Werte können auf Lagerprobleme hinweisen, die oft von zu hohen Temperaturen kommen. |
| Start/Stop Count | Unkritisch. Zählt die Start/Stop-Vorgänge des Laufwerks. |
| Reallocated Sector Count | Sehr kritisch. Zählt, wieviele Reservesektoren die Festplatte bereits genutzt hat. Deutet auf Medienprobleme hin. |
| Read Channel Margin | Gibt an, wie viel der Bandbreite bei Lesevorgängen im Mittel genutzt wird. Die genaue Bedeutung ist undokumentiert. |
| Seek Error Rate | Kritisch. Zählt die Fehler bei Lesevorgängen, die vom Zustand des Positionierungssystems, oder von der Oberfläche abhängig sind. |
| Seek Time Performance | Allgemeiner Wert, der die Leistung der Leseköpfe beschreibt. Niedrige Werte weisen auf Mechanische Probleme hin. |
| Power On Hours Count | Zählt die Betriebsstunden der Platte. Meist in einem herstellerspezifischen Format. |
| Spin Retry Count | Kritisch. Gibt an, wie oft der Motor anlaufen musste, damit die Platte ihre betriebstypische Umdrehungszahl erreicht. |
| Recalibration Retries | Kritisch. Zählt, wie oft die Platte die Schreib-Leseköpfe neu kalibrieren musste. Weißt auf mechanische Fehlfunktionen hin. |
| Device Power Cycle Count | Zeigt die Statistik, wie oft das Laufwerk ein- und ausgeschaltet wurde. |
| Soft Read Error Rate | Gibt an, wie oft das Betriebssystem die gelesenen Daten als fehlerhaft verworfen hat. |
| G-Sense Error Rate | G-Sense steht für einen Schock-Sensor, der heftige Erschütterungen im Betrieb misst. |
| Power-Off Retract Cycle | Zählt lediglich, wie oft die Festplatte abgeschaltet wurde. |
| Load/Unload Cycle Count | Gibt an, wie oft die Platte ihre Schreib- und Leseköpfe in die Parkposition (Landing Zone) gefahren hat. |
| Temperature | Gibt die Temperatur des Laufwerks an. Eher unwichtig, da die Messung bei den meisten Geräten sehr ungenau ist. |
| Reallocation Events Count | Sehr kritisch. Zählt jeden Versuch der Platte, Sektoren umzumappen, auch wenn dies nicht gelingt. |
| Current Pending Sector Count | Sehr kritisch. Gibt die Anzahl der instabilen Sektoren an, die auf eine Verschiebung in den reservierten Bereich warten. |
| Uncorrectable Sector Count | Sehr kritisch. Die Anzahl der fehlerhaften Sektoren, welche die interne Plattenlogik nicht restaurieren und in den reservierten Bereich verschieben kann. |
| UltraDMA CRC Error Rate | Kritisch. Anzahl der Prüfsummenfehler bei der Datenübertragung. Kann auch auf defekte Kabel, Treiberkonflikte oder auf Übertaktungsprobleme hinweisen. |
| Write Error Rate | Kritisch. Zählt, wie oft Fehler beim Schreiben von Sektoren aufgetreten sind. |
| Disk Shift | Sehr Kritisch. Dieser Wert gibt an, ob sich aufgrund von Temperaturproblemen oder Schockeinwirkungen eine Umwucht gebildet hat. |
| Loaded Hours | Gibt an, wie lange die Platte unter Volllast stand. Der Indikator dafür sind die Bewegungen des Plattenarms. |
| Load/Unload Retry Count | Zählt in einer undokumentierten Einheit, wie oft die Schreib-Leseköpfe die Position geändert haben. |
| Load Friction | Zeigt einen statistischen Wert, wie hoch der Reibungswiderstand beim Bewegen des Plattenarmes ist. |
| Load-in Time | Gibt an, wie lange sich der Plattenarm nicht in der Landing Zone geparkt war. |
| Torque Amplification Count | Zählt, wie oft die interne Logik der Platte das Drehmoment neu anpassen musste. |
| GMR Head Amplitude | Ein rein statistischer Wert über die zurückgelegte Distanz der Schreib-Leseköpfe während einer Bewegung. |
Messwert-Attribute
| Attribut | Bedeutung |
|---|---|
| VALUE | ist ein normalisierter Messwert, der zumeist rückwärts zählt (je niedriger, desto schlechter). |
| WORST | der bisher schlechteste Wert. |
| THRESHOLD | die Grenze, unter die der Wert nicht fallen darf. |
| TYPE | steht für die Bedeutung des Parameters: Pre-fail ist eine Warnung vor einem baldigen Ausfall, während Old age bedeutet dass es sich allgemein um fortschreitende Alterung handelt. (Die aktuelle Temperatur fällt nicht unbedingt in eine der beiden Kategorien) |
| UPDATED | zeigt an, ob der Wert permanent (always) oder erst durch einen Selbsttest vom Typ Offline data collection aktualisiert wird. |
| RAW_VALUE | ist der eigentliche Messwert, also etwa die gemessene Temperatur oder die Zahl der Fehler. |
Erstellung eines Kompletten SMART Logs
Um einen Kompletten SMART Log zu erstellen führt man smartctl mit der option -x aus. Die Angabe der Festplatte erfolgt analog der Erklärung unter Hinweise zu defekten Festplatten.
SMART Selbsttest starten
Den Selbsttest der Festplatte kann man mit smartctl und der Option -t short oder -t long starten. Die Angabe der Festplatte erfolgt analog der Erklärung unter Hinweise zu defekten Festplatten.
Dieser Selbsttest ist ein Hersteller spezifischer Test, der von der Festplattenfirmware durchgeführt wird. Der Server sollte während des Tests nicht weiter beansprucht werden, da dies den Test abbrechen könnte.
Festplatten in RAID-Controllern
Unter Windows
Um Festplatteninformationen aus einem RAID-System zu entnehmen, entwickelte Adaptec ein Tool zur Administration dieser Systeme. Dieses Programm ist grafisch aufgebaut und heißt Adaptec Storage Manager. Du kannst es hier herunterladen. Benutze hierzu die in der Bestätigungsemail geschickten Benutzerdaten.
Installiere das Programm auf deinem Server und starte es. Danach sollte eine grafische Oberfläche erscheinen, mit der du administrieren kannst.
Als Nächstes klickst du links in der Box auf Direct Attached Storage. Blick rechts in das Auswahlmenü und wähle mit einem Doppelklick das installierte Betriebssystem, mit der entsprechenden IP und dem entsprechenden System. Es sollte eine Abfrage nach den Anmeldedaten erfolgen. Nachdem du dich angemeldet hast, erscheint eine Meldung, dass ein RAID-Controller gefunden wurde. Bestätige mit Register Later und klicke dann mit einem Doppelklick auf den RAID-Controller.
Nun erscheint eine Liste, in der sich alle Festplatten an dem RAID-Controller befinden. Wähle deine Festplatte mit einem Doppelklick aus. Es öffnet sich ein Fenster, wo du die Festplatteninformationen abrufen kannst.
Unter Linux
smartctl zeigt in der Regel die Seriennummer der Festplatte an, es gibt jedoch für diverse Controller auch spezielle Programme:
3ware Controller
Hier wird tw_cli benötigt. Es sollte in den Paketquellen der Distributionen enthalten sein. Man startet tw_cli ohne Angabe von Parametern:
tw_cliDer Aufruf erfolgt nun wie folgt:
/cx/py show serialx steht für die Controller-Nr, bei einem 0 y für die Nr der Festplatte
Adaptec Controller
Unter Linux benötigst du ein Tool namens arcconf. Dieses Programm kannst du dir hier herunterladen.
Entpacke die Datei. Verschiebe anschließend die Datei:
mv arcconf-64 /usr/local/binAnschließend machst du die arcconf zu einer ausführbaren Datei:
chmod +x /usr/local/bin/arcconfFühre nun die Datei aus:
/usr/local/bin/arcconfMöglicherweise musst du libstdc++5 mitinstallieren, da arcconfig dieses Paket benötigt. Falls dies der Fall sein sollte, kannst du dir hier die Datei herunterladen.
Wenn eine Liste mit möglichen Befehlsparametern erscheint, arbeitet das Programm korrekt.
Nun kannst du mit dem Befehl ./usr/local/bin/arcconf getconfig 1 die Seriennummer der Festplatte auslesen. Dabei gibt die Zahl 1 an, um welchen RAID-Controller es sich handelt.
Beachte jedoch, dass deine Festplatten im RAID erst ab Physical Device information aufgelistet werden. Du findest die Seriennummer deiner Festplatten in Serial number.
Neben den Seriennummern findest du mit diesem Tool weitere nützliche Informationen zu deinen Festplatten.
Unter FreeBSD
Um die Festplattenseriennummer aus FreeBSB zu bekommen, musst du folgende Befehle in das Terminal eingeben:
portsnap fetch update
cd /usr/ports/sysutils/arcconf
make install clean && rehashMit dem Befehl /usr/local/sbin/arcconf getconfig 1 kannst du auf die Festplatten zugreifen. Achte auch hierbei darauf, dass die Zahl hinter getconfig, den RAID Controller angibt.
Wie auch unter Linux findest du sämtliche Festplatteninformationen, u.a. auch die Serial number, in den Physical Device information.